Script to adapt the PDF size
A big gap of my eBook reader, the Asus DR900, is the maximum page zoom fixed to 200%. Generally the 200% works fine for most PDF file, but when I try to read PDF that includes double pages or document in A4 with A3 pages, the reading become very difficult. So I wrote a little bash script called set-uniform-pagination.sh that halves the pages exceeding the horizontal dimension of the first.
I bought an eBook reader too for reading easily and without using PC, my online journal, il Fatto Quotidiano. I am a subscriver of their annual PDF version, that I can download following two possibility:
- Through a web app called Active Paper by Olive Software. It is possible to read online the journal or to download the PDF, which has these specification: Acrobat Distiller 7 is the producer and version is 1.6. The file is heavy and contains pages in double face like the paper version.
- Through a direct link in the user subscriver page. This PDF is three times smaller than the previous one and doesn't contain double pages. The PDF specifications: PDFsharp 1.2.1269-g is the producer and version is 1.4.
On my PC I have never had any problem with the two types of PDF described above. Otherwise on my eBook reader I have too much problems. With the first it become heavy and difficult the scrolling when the page is full of graphic and in the double page the reading is difficult too at 200% scale zoom. With the second file some time the reader block itself in changing page or in scrolling.
Anyway my nature is stubborn and stingy (i.e. every acquired product should well satisfy my needs). So I should find a solution. Firstly I have tried in Internet and then I wrote a few rows of code. The final bash script works for all the PDFs that contain two type of page: one as reference and the other with double in horizontal dimension than the first. The final specifications: producer is GPL Ghostscript 8.71, version is 1.4 and page format is ISO A4. The final dimension may change respect of the option defined. The default is ebook and the file is halved than the case 1. It is possible edit the script and change this option in screen, in this way the file it is reduced of a third but photos, diagrams and sketchs become not clearly defined.
How it works
Simply like in the following example:
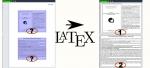
- doppia_facciata.pdf is a document that contains 3 pages, the second is in double face;
- in the bash shell I run the script in this way:
./set-uniform-pagination.sh doppia_facciata.pdf
- I obtain the final file called doppia_facciata_ebook.pdf.
| Input: | Output: |
 |  |
set-uniform-pagination.sh
In order to execute it, the requirements are:
- bash shell;
- pdfinfo, to read total number of pages and the exact dimension of every page;
- awk, to parsing and select the pdfinfo output;
- LaTeX with pdfpages package to include PDFs pages and ifthen package to give the ability of the conditional instructions;
- Ghostscript to optimize the resulting LaTeX file;
- if the first PDF page is double, it is necessary to edit script and change the default reference page to another one.
The script is well commented and short, it reads the PDF information (number of pages and theirs dimension one by one), it writes a LaTeX file that divides automatically the exceeding pages (comparing to the first one take as a reference), finally it compiles the tex file with pdflatex and optimizes it with gs command and ebook option .
Here is zip file with the script: Script_to_PDF_uniform.zip
Obviously it is possible to edit it and to change its features like: format (default ISO A4), paper orientation (default portrait), reference page (default 1), and much more!
For lazy people here is the script code:
#!/bin/bash
# Script written by Nicola Rainiero
# Available at http://rainnic.altervista.org
#
# This work is licensed under the Creative Commons Attribution 3.0 Italy License.
# To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/it/
#
# Requirements: pdfinfo, awk, LaTex with pdfpages and ifthen packages,ghostcript
# Usage: set-uniform-pagination.sh INPUT_FILE.pdf
#
if [ -n "$1" ]
then
document=$1 # check if exist an input PDF file
else
echo Missing input PDF 'file'!!
exit 0
fi
echo $document
# read the exact number of page in the PDF file and write it in "pagine" variable
echo `pdfinfo $document | awk ' $1=="Pages:" {print $2}'` > input.txt
pagine=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $pagine
echo '% File di conversione' > latex.tex
# initialize the latex document: the default page layout is "portrait"
# to have the whole document pages changed to "landscape"
echo '\documentclass[a4paper,portrait]{minimal}' >> latex.tex;
echo '\usepackage[pdftex,portrait]{geometry}' >> latex.tex;
echo '\usepackage{pdfpages}' >> latex.tex;
echo '\usepackage{ifthen}' >> latex.tex;
echo '\newcounter{pg}' >> latex.tex;
echo '\begin{document}' >> latex.tex;
# read the horizontal dimension of the first page ("-f 1" option) and save it in: rifh
echo `pdfinfo -f 1 -box $document | awk ' $1=="MediaBox:" {print $4}'` > input.txt
rifh=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $rifh
# read the vertical dimension of the first page ("-f 1" option) and save it in: rifv
echo `pdfinfo -f 1 -box $document | awk ' $1=="MediaBox:" {print $5}'` > input.txt
rifv=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $rifv
echo
# check for every page the corresponding horizontal dimension
# and compare it with the "rifh" variable
for i in `seq 1 $pagine`
do
echo `pdfinfo -f $i -box $document | awk ' $1=="MediaBox:" {print $4}'` > input.txt
h=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $h
if [[ "$h" -gt "$rifh+200" ]]
then
echo 'split' page
echo ' \includepdf[pages='$i',viewport=0 0 '$rifh' '$rifv']{'$document'} ' >> latex.tex;
echo ' \includepdf[pages='$i',viewport='$rifh' 0 '$h' '$rifv']{'$document'} ' >> latex.tex;
else
echo 'do' not 'split' page
echo ' \includepdf[pages='$i',viewport=0 0 '$rifh' '$rifv']{'$document'} ' >> latex.tex;
fi
done
# close the latex document and make pdf --> latex.pdf
echo '\end{document} ' >> latex.tex;
pdflatex latex.tex
# save in "nomefile" variable the exact name of the input file
nomefile=${1%%.*}
echo $nomefile
# optimize latex.pdf and rename it in "nomefile" plus the ebook label
gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -dNOPAUSE -dQUIET -dBATCH -sOutputFile="$nomefile"_ebook.pdf latex.pdf
# clean up useless files
rm input.txt
rm latex*
exit 0











Add new comment