Script to add bookmarks and toc in PDFs
In the previous article I explain how to insert toc and/or bookmarks using LaTeX in a PDF document, omitting a very boring aspect: selection and writing of all parts that you want insert in these ones (avoiding errors when the items are very numerous!). In order to automate this procedure, I wrote a small bash script that converts the output made by JPDFBookmarks in a text file pasteable in LaTeX.
In How to add a clickable TOC to a PDF file article, you learned to insert table of contents and/or bookmarks in PDF files with a few rows of code. But in my example I used only 7 items, in a book generally there are also several dozen of chapters and sections... How many errors could I have done to insert them? How much time should I spend to do this?
Don't worry! I have the solution:
- JPDFBookmarks (a Java PDF bookmarks editor with GUI) to insert and edit easily all the items that you need, and then export these in a text file;
- my bash script, convert_bookmarks.sh, to convert the saved file in a code that you can paste in a LaTeX document..
Requirements
In order to execute it, the requirements are:
Then for LaTeX:
- geometry, to define the exact size of the paper and to setup the position of page number from bottom;
- pdfpages, to include PDF pages in a LaTeX document;
- hyperref, to transform the output PDF in a hypertext;
- color, to enlarge the default number of colors (set to eight).
How it works
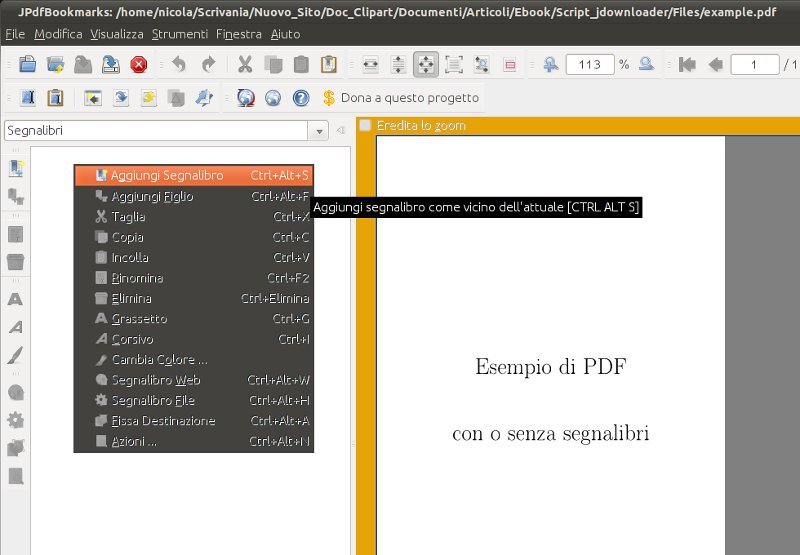
Firstly you have to execute JPDFBookmarks, edit bookmark page after page, clicking Add bookmark and/or Add child you can decide the degree of relationship (are only available 4 degrees), in this order:
- Add bookmark --> chapter
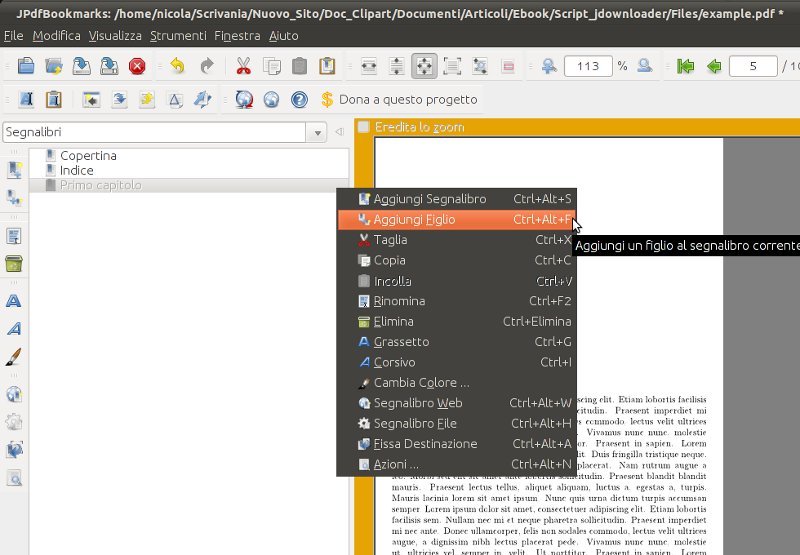
- Add child --> section
- Add child --> sub-section
- Add child --> sub-sub-section
The tabulations on screen let you to see this relationship among items and using mouse you can fix the errors in definitions.
Make Attention: when you edit or type bookmark title, do not use "/", because this is a special character that JPDFBokkmarks uses to separate the pages and so my script too!
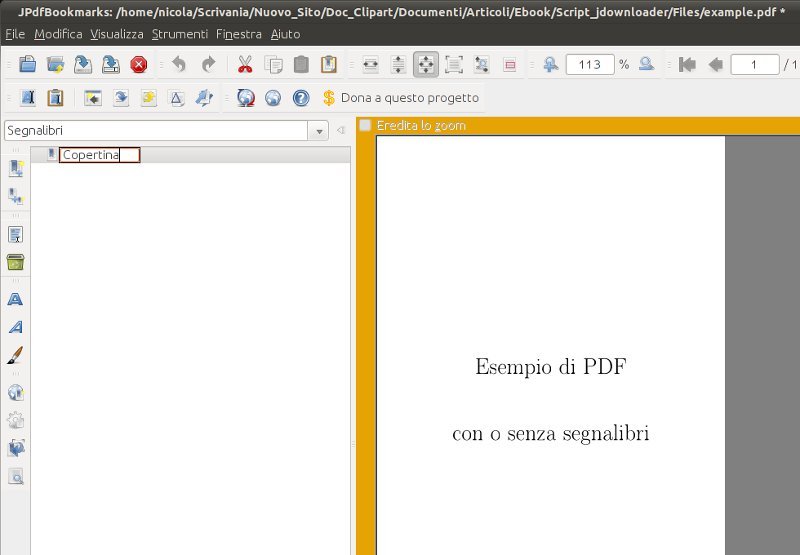
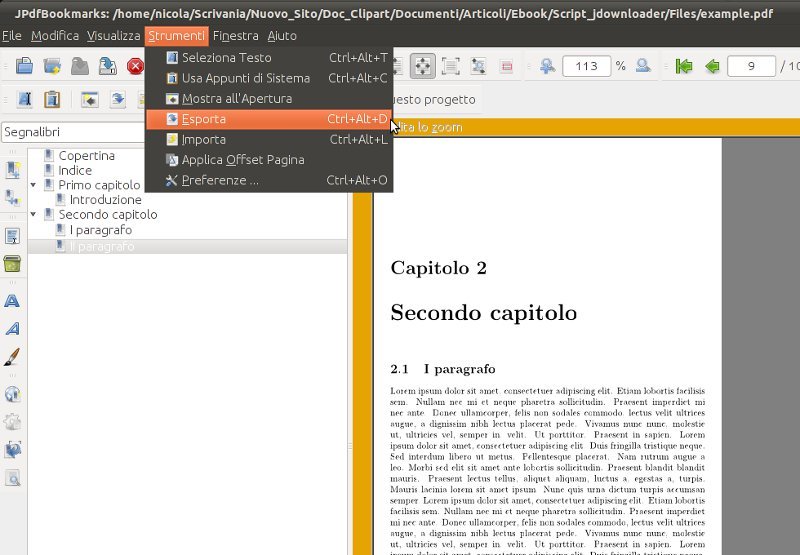
Once you have inserted all bookmarks, you can click on Tools in the upper menu and than the Export item. Save your bookmarks for example in a file called bookmarks.txt and close this software.
In a shell window launch my bash script with the last saved file (in the same directory of course):
./convert_bookmarks.sh bookmarks.txt
If the script has lost the execute permission, use this command:
chmod +x convert_bookmarks.sh
The output will be in this case bookmarks_for_latex.txt that you can paste inside an includepdf call on a opened LaTeX file.
Handy example
I use the classical PDF without bookmarks and I add all bookmarks with JPDFBookmarks. In the follow gallery I describe these elementary operations:
 |  |  |
 |  |  |
I export my bookmarks in bookmarks.txt:
Copertina/1,Black,notBold,notItalic,closed,FitPage
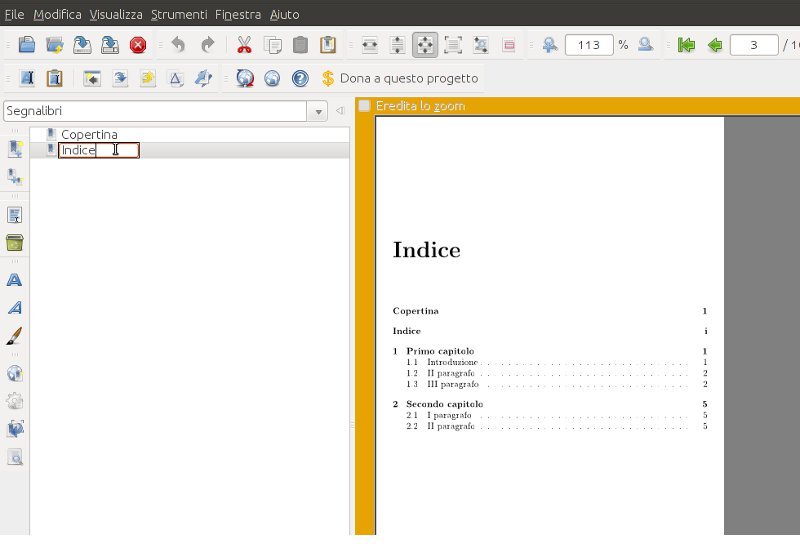
Indice/3,Black,notBold,notItalic,closed,FitPage
Primo capitolo/5,Black,notBold,notItalic,open,FitPage
Introduzione/5,Black,notBold,notItalic,closed,FitPage
Secondo capitolo/9,Black,notBold,notItalic,open,FitPage
I paragrafo/9,Black,notBold,notItalic,open,FitPage
II paragrafo/9,Black,notBold,notItalic,closed,FitPage LaTeX does not understands it! My script however can help, transforming it in bookmarks_for_latex.txt:
1,chapter,1,{Copertina},a,
3,chapter,1,{Indice},a,
5,chapter,1,{Primo capitolo},a,
5,section,1,{Introduzione},a,
9,chapter,1,{Secondo capitolo},a,
9,section,1,{I paragrafo},a,
9,section,1,{II paragrafo},a, I can insert this piece of code inside an includepdf call, remembering to remove the last comma in the final bookmark.
I open a LaTeX document, named addtex.tex so described:
\documentclass{book}
\usepackage[paperwidth=383pt,paperheight=696pt,includeheadfoot,margin=2.5pt]{geometry}
\usepackage{pdfpages}
\author{Nicola Rainiero}
\title{Esempio di PDF con indice cliccabile}
\usepackage[pagebackref]{hyperref}
%\setcounter{secnumdepth}{-2} %chapters, sections and subsections without numbering in the TOC
\begin{document}
\mainmatter
\includepdf[pages={1-10},addtotoc={
1,chapter,1,{Copertina},a,
3,chapter,1,{Indice},a,
5,chapter,1,{Primo capitolo},a,
5,section,1,{Introduzione},a,
9,chapter,1,{Secondo capitolo},a,
9,section,1,{I paragrafo},a,
9,section,1,{II paragrafo},a
}]{example.pdf}
\end{document} Instead this is convert_bookmarks.sh script:
#!/bin/bash
# Script written by Nicola Rainiero
# Available at http://rainnic.altervista.org
#
# This work is licensed under the Creative Commons Attribution 3.0 Italy License.
# To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/it/
#
# Requirements: awk and sed
# Usage: ./convert_bookmarks.sh INPUT_FILE.txt
#
#
# References:
# http://wiki.ubuntu-it.org/Programmazione/LinguaggioBash
# http://www.linuxforums.org/forum/programming-scripting/117313-ksh-bash-read-file-including-delimiters.html
#
if [ -n "$1" ]
then
document=$1 # check if exist an input TXT file
else
echo Missing input TXT 'file'!!
exit 0
fi
nomefile=${1%%.*}
echo > "$nomefile"_for_latex.txt
# initialize external text file
while IFS= read -r LINE
# read everything including tabs and spaces
do
VAR=$LINE
echo "$LINE" | awk '{print gsub(/\t/,"")}' > count.txt
# count the number of tabulation
while read count
do
number=$count
done < count.txt
case $number in
0) part='chapter,1';;
1) part='section,1';;
2) part='subsection,1';;
*) part='subsubsection,1';;
esac
VAR0=${VAR%%/*}
VAR0=$(echo $VAR0 | sed 's/^[ \t]*//')
VAR1=${VAR#*/}
page=${VAR1%%,*}
case $number in
0) echo $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
1) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
2) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
*) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
esac
done < $1
rm count.txt
exit 0
Here is zip file with the script, PDF and TEX files: Script_for_bookmarks.zip











Add new comment