Script per dotare i PDF di segnalibri e indici
L'aspetto più noioso e lento della procedura descritta per la creazione degli indici e/o dei segnalibri con LaTeX è la ricerca e l'immissione di tutte le parti che si vogliono includere in essi, rispettando il codice richiesto da pdfpages e l'esatta posizione della pagina nel documento. Per velocizzare il tutto ho scritto un piccolo script in bash che converte l'output prodotto da JPDFBookmarks in un file di testo da copiare in LaTeX.
Nell'articolo precedente, Aggiungere un indice cliccabile ad un PDF, ho spiegato come con poche righe sia possibile dotare qualsiasi PDF di un buon indice e allo stesso tempo dei segnalibri, indispensabili per migliorarne la lettura a video e con i vari eBook reader. Nell'esempio ho incluso solo 7 voci all'indice, ma se avessi dovuto includerne un numero maggiore sarebbe stato altrettanto facile e veloce? E quanti errori dovuti a sintassi errata o negligenza avrei potuto commettere?
Niente paura! Ho la soluzione a questo tedioso problema:
- JPDFBookmarks (un comodo editor java di segnalibri per PDF) per inserire ed editare a video tutte le voci che si vogliono e poi esportarle in un file di testo;
- il mio script, convert_bookmarks.sh, per convertire il file appena salvato in un codice LaTex da includere nel documento finale che poi una volta compilato restituirà il PDF finale.
Requisiti
Per poterlo usare bisogna avere:
- shell testuale bash, per eseguire lo script;
- awk e sed, per estrapolare ed interpretare le tabulazioni presenti nel file esportato da JPDFBookmarks.
Poi per la compilazione con LaTeX serviranno i seguenti pacchetti:
- geometry, per definire le dimensioni del foglio e impostare la posizione del numero della pagina dal fondo;
- pdfpages, per includere le pagine dei PDF in un documento LaTeX;
- hyperref, per rendere il PDF un ipertesto;
- color, per definire nuovi tipi di colore oltre agli otto standard.
Funzionamento
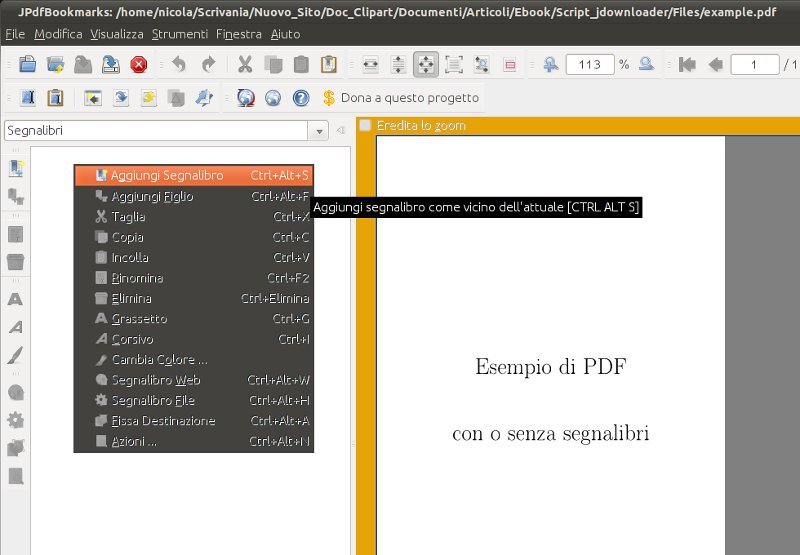
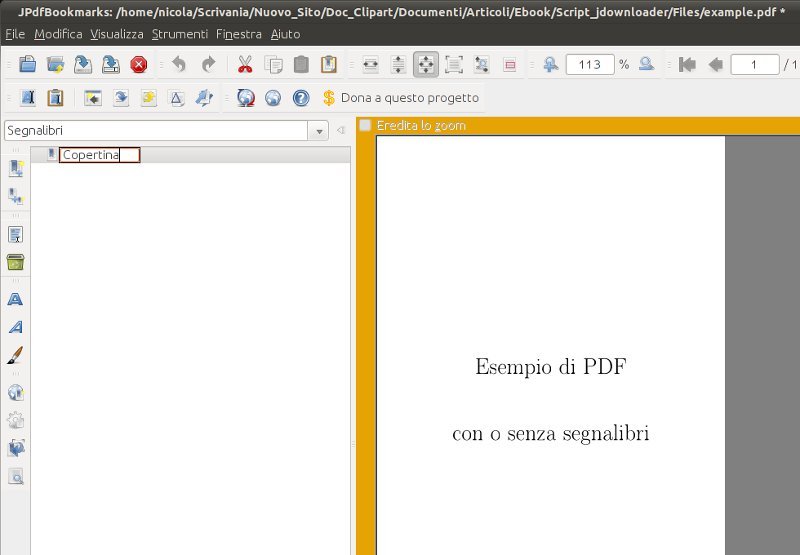
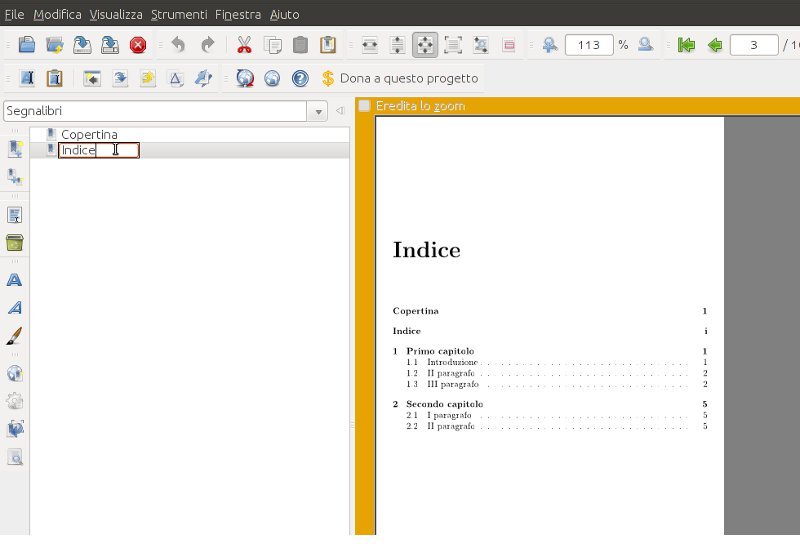
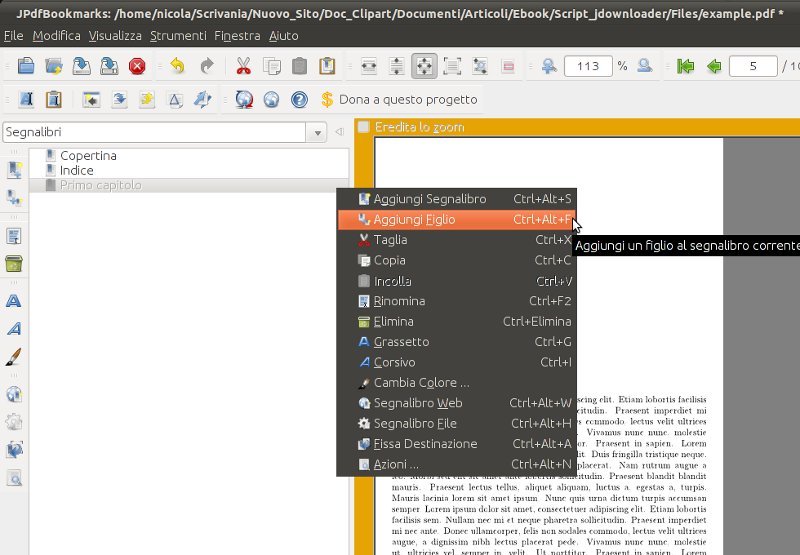
Si carica il PDF da sistemare in JPDFBookmarks, si editano i segnalibri pagina per pagina, utilizzando la funzione Aggiungi segnalibro e/o Aggiungi figlio per ricreare la gerarchia delle voci (sono possibili alo massimo quattro livelli), in questo ordine:
- Aggiungi segnalibro --> capitolo
- Aggiungi figlio --> paragrafo
- Aggiungi figlio --> sotto-paragrafo
- Aggiungi figlio --> sotto-sotto-paragrafo
Le tabulazioni a video permettono di vedere questa gerarchia ed eventualmente con il mouse si può intervenire per correggere gli errori di assegnazione.
N.B. Quando si da il nome al segnalibro bisogna evitare il carattere "/" perché è il simbolo utilizzato di default dal programma per separare le pagine e quindi di riflesso anche dal mio script.
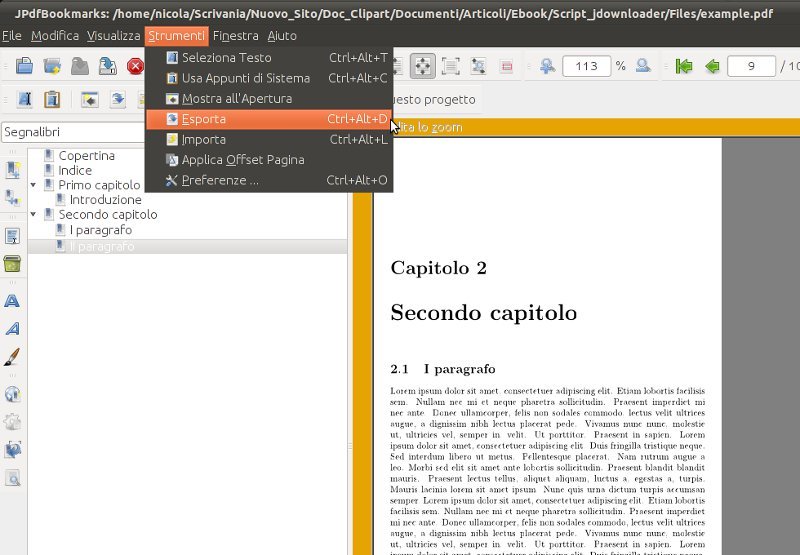
Una volta inseriti tutti i segnalibri si clicca sul menu in alto la voce Strumenti e poi nel menu a discesa Esporta, si salva il file per esempio nominandolo bookmarks.txt ed il gioco è fatto!
Si lancia lo script bash facendolo seguire dal nome del file appena salvato (deve risiedere nella stessa directory):
./convert_bookmarks.sh bookmarks.txt
Se non fosse eseguibile si può sempre da shell lanciare il seguente comando:
chmod +x convert_bookmarks.sh
Ne uscirà un file di testo denominato in questo caso bookmarks_for_latex.txt che può essere incollato opportunamente all'interno di includepdf nel file LaTeX.
Esempio pratico
Utilizzo il solito file PDF senza segnalibri e creo tutti i bookmark che mi interessano con JPDFBookmarks. La seguente galleria fotografica può essere di aiuto:
 |  |  |
 |  |  |
Dopo averlo esportato otterrò bookmarks.txt così definito:
Copertina/1,Black,notBold,notItalic,closed,FitPage Indice/3,Black,notBold,notItalic,closed,FitPage Primo capitolo/5,Black,notBold,notItalic,open,FitPage Introduzione/5,Black,notBold,notItalic,closed,FitPage Secondo capitolo/9,Black,notBold,notItalic,open,FitPage I paragrafo/9,Black,notBold,notItalic,open,FitPage II paragrafo/9,Black,notBold,notItalic,closed,FitPage
Ovviamente LaTeX non lo può interpretare! Uso allora il mio script che restituisce il seguente file bookmarks_for_latex.txt:
1,chapter,1,{Copertina},a,
3,chapter,1,{Indice},a,
5,chapter,1,{Primo capitolo},a,
5,section,1,{Introduzione},a,
9,chapter,1,{Secondo capitolo},a,
9,section,1,{I paragrafo},a,
9,section,1,{II paragrafo},a,Questo codice posso inserirlo facilmente all'interno di includepdf ricordando però di togliere la virgola finale dall'ultima voce.
Creo quindi un documento LaTeX chiamato addtex.tex così definito:
\documentclass{book}
\usepackage[paperwidth=383pt,paperheight=696pt,includeheadfoot,margin=2.5pt]{geometry}
\usepackage{pdfpages}
\author{Nicola Rainiero}
\title{Esempio di PDF con indice cliccabile}
\usepackage[pagebackref]{hyperref}
%\setcounter{secnumdepth}{-2} %per avere capitoli, sezioni e sottosezioni non numerate nell'indice
\begin{document}
\mainmatter
\includepdf[pages={1-10},addtotoc={
1,chapter,1,{Copertina},a,
3,chapter,1,{Indice},a,
5,chapter,1,{Primo capitolo},a,
5,section,1,{Introduzione},a,
9,chapter,1,{Secondo capitolo},a,
9,section,1,{I paragrafo},a,
9,section,1,{II paragrafo},a
}]{example.pdf}
\end{document}Questo invece è lo script vero e proprio convert_bookmarks.sh:
#!/bin/bash
# Script written by Nicola Rainiero
# Available at http://rainnic.altervista.org
#
# This work is licensed under the Creative Commons Attribution 3.0 Italy License.
# To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/it/
#
# Requirements: awk and sed
# Usage: ./convert_bookmarks.sh INPUT_FILE.txt
#
#
# References:
# http://wiki.ubuntu-it.org/Programmazione/LinguaggioBash
# http://www.linuxforums.org/forum/programming-scripting/117313-ksh-bash-read-file-including-delimiters.html
#
if [ -n "$1" ]
then
document=$1 # check if exist an input TXT file
else
echo Missing input TXT 'file'!!
exit 0
fi
nomefile=${1%%.*}
echo > "$nomefile"_for_latex.txt
# initialize external text file
while IFS= read -r LINE
# read everything including tabs and spaces
do
VAR=$LINE
echo "$LINE" | awk '{print gsub(/\t/,"")}' > count.txt
# count the number of tabulation
while read count
do
number=$count
done < count.txt
case $number in
0) part='chapter,1';;
1) part='section,1';;
2) part='subsection,1';;
*) part='subsubsection,1';;
esac
VAR0=${VAR%%/*}
VAR0=$(echo $VAR0 | sed 's/^[ \t]*//')
VAR1=${VAR#*/}
page=${VAR1%%,*}
case $number in
0) echo $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
1) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
2) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
*) echo " " $page,$part,{$VAR0},a, >> "$nomefile"_for_latex.txt;;
esac
done < $1
rm count.txt
exit 0
I PDF di questa guida, lo script bash e il file TEX sono stati compressi qui: Script_for_bookmarks.zip
Sitografia
Per la stesura di questo articolo e l’ottimizzazione di alcune funzioni ho consultato questi due siti:











Aggiungi un commento