Script per uniformare i PDF
Un grave difetto del mio eBook reader, l'Asus DR900, è l'impossibilità di ingrandire le pagine oltre il 200%, in genere non è un problema così grave ma quando cerco di leggere PDF che contengono anche pagine affiancate come quotidiani o documenti in formato A4 con inserti in A3, allora sono cavoli amari! Per sopperire a questa lacuna ho realizzato set-uniform-pagination.sh, uno script bash che illustrerò nell'articolo.
Uno dei motivi che mi ha spinto a comprare questo apparecchio è stata anche la presunzione di poter finalmente leggere in santa pace e senza stare attaccato al monitor del PC il Fatto Quotidiano, giornale di cui ho un abbonamento PDF annuale. Il loro sito offre due possibilità per scaricarlo:
- Tramite ActivePaper Daily di Olive Software, che permette di leggerlo on-line e di salvarlo sul proprio PC. Questa versione è molto pesante e contiene alcune pagine affiancate. Le specifiche del file scaricato indicano che è stato realizzato con Acrobat Distiller 7.0 in versione 1.6.
- Tramite il link diretto disponibile nella pagina abbonati. Questa versione è tre volte più piccola della precedente e non contiene pagine affiancate. Leggendo le specifiche del PDF salvato si scopre che è stato realizzato con PDFsharp 1.2.1269-g, in versione 1.4.
Sul computer non ho mai avuto problemi con le due tipologie di file sopra descritte, ma sul lettore purtroppo tanti: le pagine affiancate del primo caso anche ingrandendole al 200% sono illeggibili, il secondo invece di tanto in tanto mi fa piantare il dispositivo o per lo meno devono passare svariati minuti per passare da una pagina all'altra.
Fermo restando che sono testardo di natura e taccagno per definizione, ho voluto trovare una soluzione a questo problema, dapprima cercando su internet e poi provando a scrivere qualche riga di codice. Alla fine ne è uscito uno script bash che mi consente di uniformare la prima versione e ridurla in un formato più digeribile all'eBook reader. Le specifiche finali recitano: GPL Ghostscript 8.71, versione 1.4 e formato in tutti i casi portato ad ISO A4 per tutte le pagine. Per quanto riguarda la dimensione del file posso scegliere se ottimizzarlo come “ebook” e allora si riduce della metà rispetto al PDF più pesante (possibilità 1) oppure con l'opzione “screen” si riduce di oltre un terzo, ma foto, diagrammi e soprattutto le vignette diventano troppo sgranati.
Il funzionamento
Prima di passare allo script ne mostro il funzionamento con un esempio pratico:
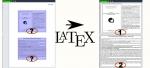
- doppia_facciata.pdf è un documento che contiene 3 pagine: la seconda è in doppia facciata;
- da shell lancio lo script in questo modo:
./set-uniform-pagination.sh doppia_facciata.pdf
- ottenendo come file finale doppia_facciata_ebook.pdf.
| File in ingresso: | File restituito: |
 |  |
Lo script set-uniform-pagination.sh
Per poterlo usare bisogna avere i seguenti prerequisiti:
- shell testuale bash, per poter eseguire lo script;
- pdfinfo, per leggere il numero di pagine complessive che costituiscono il PDF e le dimensioni orizzontali e verticali di ogni pagina;
- awk, per estrapolare le variabili prodotte da pdfinfo;
- LaTeX con i pacchetti pdfpages per includere pagine PDF nei documenti e ifthen per poter inserire comandi condizionali;
- Ghostscript per ottimizzare il file pdf ottenuto;
- Se la prima pagina del PDF è in doppia facciata, bisogna editare lo script e sostituirla con un'altra singola.
Senza entrare troppo nei dettagli tecnici (basta editarlo e leggere i commenti inseriti) il suo funzionamento si può descrivere in questo modo: lettura delle informazioni che costituiscono il PDF di input (numero totale e dimensioni delle singole pagine), scrittura di un opportuno file LaTeX che si occupa di dividere le pagine eccedenti la dimensione orizzontale della prima (presa come riferimento) a metà, compilazione del file generato con il comando pdflatex e ottimizzazione con il comando gs di ghostscript.
Ecco l'archivio zip con lo script per il download: Script_to_PDF_uniform.zip
Ovviamente si può modificare a seconda delle proprie esigenze cambiando per esempio: il formato (A4 nello script), l'orientazione della carta ad orizzontale (da “portrait” a “landscape”), la pagina di riferimento, e molto altro.
Per i più pigri ecco il codice dello script:
#!/bin/bash
# Script written by Nicola Rainiero
# Available at http://rainnic.altervista.org
#
# This work is licensed under the Creative Commons Attribution 3.0 Italy License.
# To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/it/
#
# Requirements: pdfinfo, awk, LaTex with pdfpages and ifthen packages,ghostcript
# Usage: set-uniform-pagination.sh INPUT_FILE.pdf
#
if [ -n "$1" ]
then
document=$1 # check if exist an input PDF file
else
echo Missing input PDF 'file'!!
exit 0
fi
echo $document
# read the exact number of page in the PDF file and write it in "pagine" variable
echo `pdfinfo $document | awk ' $1=="Pages:" {print $2}'` > input.txt
pagine=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $pagine
echo '% File di conversione' > latex.tex
# initialize the latex document: the default page layout is "portrait"
# to have the whole document pages changed to "landscape"
echo '\documentclass[a4paper,portrait]{minimal}' >> latex.tex;
echo '\usepackage[pdftex,portrait]{geometry}' >> latex.tex;
echo '\usepackage{pdfpages}' >> latex.tex;
echo '\usepackage{ifthen}' >> latex.tex;
echo '\newcounter{pg}' >> latex.tex;
echo '\begin{document}' >> latex.tex;
# read the horizontal dimension of the first page ("-f 1" option) and save it in: rifh
echo `pdfinfo -f 1 -box $document | awk ' $1=="MediaBox:" {print $4}'` > input.txt
rifh=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $rifh
# read the vertical dimension of the first page ("-f 1" option) and save it in: rifv
echo `pdfinfo -f 1 -box $document | awk ' $1=="MediaBox:" {print $5}'` > input.txt
rifv=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $rifv
echo
# check for every page the corresponding horizontal dimension
# and compare it with the "rifh" variable
for i in `seq 1 $pagine`
do
echo `pdfinfo -f $i -box $document | awk ' $1=="MediaBox:" {print $4}'` > input.txt
h=$(cat input.txt | awk '{ SUM += $1} END { print SUM }')
echo $h
if [[ "$h" -gt "$rifh+200" ]]
then
echo 'split' page
echo ' \includepdf[pages='$i',viewport=0 0 '$rifh' '$rifv']{'$document'} ' >> latex.tex;
echo ' \includepdf[pages='$i',viewport='$rifh' 0 '$h' '$rifv']{'$document'} ' >> latex.tex;
else
echo 'do' not 'split' page
echo ' \includepdf[pages='$i',viewport=0 0 '$rifh' '$rifv']{'$document'} ' >> latex.tex;
fi
done
# close the latex document and make pdf --> latex.pdf
echo '\end{document} ' >> latex.tex;
pdflatex latex.tex
# save in "nomefile" variable the exact name of the input file
nomefile=${1%%.*}
echo $nomefile
# optimize latex.pdf and rename it in "nomefile" plus the ebook label
gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -dNOPAUSE -dQUIET -dBATCH -sOutputFile="$nomefile"_ebook.pdf latex.pdf
# clean up useless files
rm input.txt
rm latex*
exit 0
Commenti
Ottimo script: è proprio
Ottimo script: è proprio quello che cercavo! In compenso avendo Windows non so come procedere, potresti aiutarmi?
Re: Ottimo script
Ciao Matteo, senza scomodare Windows e/o Linux, ti consiglio di leggere il mio articolo successivo: Come ritagliare e dividere un PDF online e in LaTeX ma senza usarlo. È molto più performante, facile da usare e non necessita di alcun sistema operativo.











Aggiungi un commento